基于MediaPipe的智能瑜伽姿势实时检测与校正系统
2026/7/4 14:50:50
作者:林焱
如果把RPA比作数字员工的"双手"(能操作电脑完成各种任务),那么AI就是它的"大脑"(能看、能听、能理解、能思考)。
单独的RPA就像一个严格执行指令但缺乏灵活性的工人——它能精确地点击按钮、填写表单、搬运数据,但如果页面稍微变了、图片里的文字不一样了、需要理解一段话的含义,它就会束手无策。
而当RPA遇上AI,一切都变了:
这三者与RPA的结合,催生了新一代的IPA(Intelligent Process Automation,智能流程自动化)。影刀RPA正是国内率先将AI能力深度集成到RPA产品中的先行者。这篇文章将全面介绍如何在影刀RPA中使用AI能力,让你的自动化流程从"机械执行"进化为"智能处理"。
┌─────────────────────────────────────────────────────────┐ │ 影刀RPA AI能力体系 │ ├─────────────┬─────────────┬─────────────────────────────┤ │ │ │ │ 📝 OCR │ 👁 CV │ 🧠 LLM │ │ (文字识别) │ (计算机视觉) │ (大语言模型) │ │ │ │ │ 识别图片中 │ 理解图像内容 │ 理解自然语言 │ │ 的文字内容 │ 和视觉特征 │ 进行推理和生成 │ │ │ │ ├─────────────┼─────────────┼─────────────────────────────┤ 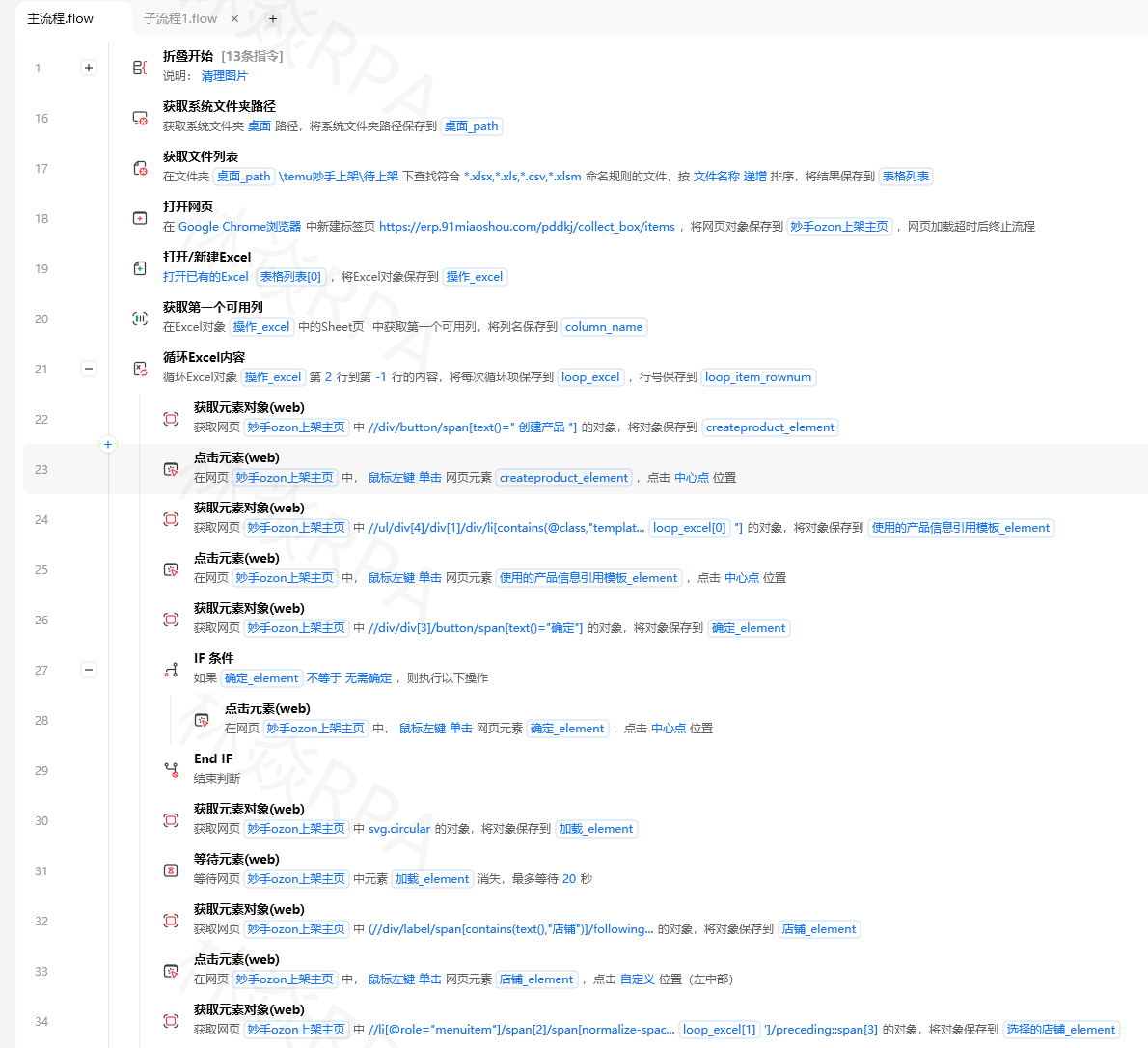 │ 典型应用: │ 典型应用: │ 典型应用: │ │ • 身份证OCR │ • 图像定位 │ • 文本智能分类 │ │ • 发票OCR │ • 图像比对 │ • 智能信息提取 │ │ • 车牌识别 │ • 物体检测 │ • 自动文案生成 │ │ • 表格识别 │ • OCR兜底 │ • 智能客服回复 │ │ • 手写字识别│ • 验证码识别 │ • 数据智能分析 │ │ │ │ • 自然 language 指令解析 │ └─────────────┴─────────────┴─────────────────────────────┘| 场景 | 传统RPA | AI增强RPA |
|---|---|---|
| 读取固定位置的文本 | 通过坐标/选择器读取 | 通过OCR任意位置的文字 |
| 处理扫描件/PDF | 无法处理 | OCR识别后提取 |
| 验证码处理 | 停住等人工 | CV自动识别处理 |
| 判断邮件意图 | 只能关键词匹配 | LLM理解语义后分类 |
| 生成回复内容 | 只能用固定模板 | LLM根据上下文生成个性化回复 |
| 非结构化数据提取 | 正则勉强应付 | LLM智能抽取结构化信息 |
| 异常情况决策 | 只能按预设规则走 | LLM理解后做出合理决策 |
拼多多店群自动化上架方案
━━━ OCR的典型应用场景 ━━━ 1. 证件识别 身份证 → 提取姓名、身份证号、地址 驾驶证 → 提取姓名、证号、准驾车型 营业执照 → 提取公司名、统一社会信用代码 银行卡 → 提取卡号、开户行 2. 票据识别 发票 → 提取发票代码、号码、金额、日期、税额 收据 → 提取金额、收款方、日期 电子回单 → 提取交易金额、双方账号、备注 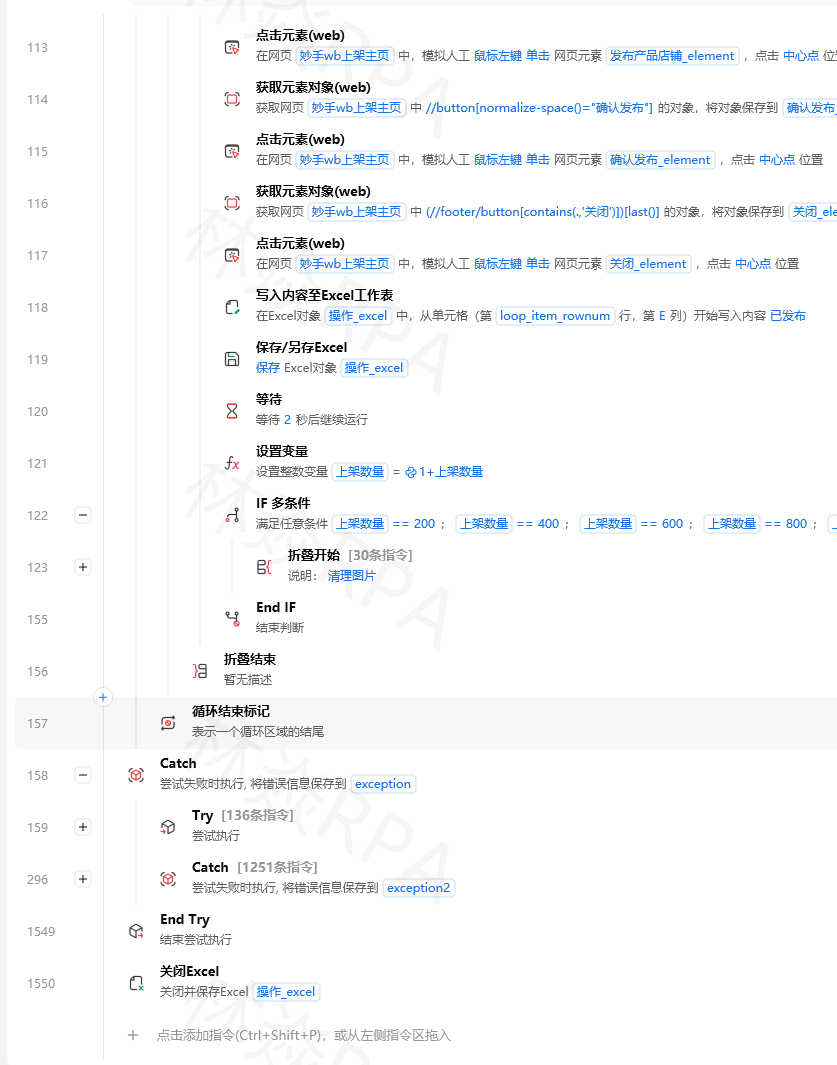 3. 屏幕文字识别 无法通过选择器获取的文字 → OCR截屏识别 远程桌面/VNC中的文字 → OCR识别 Flash/Canvas渲染的文字 → OCR识别 4. 表格/文档数字化 扫描版PDF → OCR转文字/Excel 图片表格 → OCR识别还原表格结构 手写表单 → 手写OCR识别录入场景:批量识别发票并录入系统
━━━ OCR发票识别流程 ━━━ Step 1: 获取发票图片 // 可以是从邮箱下载的附件、文件夹中的扫描件、 // 或者截取的屏幕区域 invoiceImage = GetImageFromPath("D:/invoices/inv_001.png") Step 2: 调用OCR识别 // 影刀内置OCR指令 ocrResult = OCR_Recognize( image: invoiceImage, model: "invoice", // 使用发票专用模型(精度更高) language: "zh-CN" // 中文识别 ) // 返回结果包含: ocrResult.fullText // 全部识别文本 ocrResult.fields // 结构化字段(如果是专用模型) ocrResult.confidence // 置信度分数 Step 3: 提取关键字段 发票代码 = ocrResult.fields["发票代码"] 发票号码 = ocrResult.fields["发票号码"] 金额 = ocrResult.fields["金额"] 开票日期 = ocrResult.fields["开票日期"] 销售方 = ocrResult.fields["销售方名称"] 购买方 = ocrResult.fields["购买方名称"] Step 4: 校验与录入 If ocrResult.confidence > 0.85: // 置信度够高 If ValidateInvoice(发票代码, 发票号码): 录入系统(发票代码, 发票号码, 金额, 开票日期, ...) LogInfo("发票识别录入成功: " + 发票号码) Else: LogWarn("发票校验失败,转入人工审核队列") Else: LogWarn("OCR置信度过低(" + confidence + "),需人工复核") 转入人工审核(ocrResult, invoiceImage) Step 5: 批量处理 // 对文件夹下所有发票图片重复上述流程 ForEach image in GetFiles("D:/invoices/*.png"): 处理单张发票(image) End ForEach━━━ 提升OCR识别率的最佳实践 ━━━ ✅ 图像预处理(非常重要!) 1. 图片放大:分辨率越高识别率越高(建议DPI≥300) 2. 去噪处理:去除斑点、杂线 3. 二值化:文字与背景对比度越高越好 4. 矫正倾斜:图片角度摆正 5. 裁剪边框:去掉无关背景,只保留文字区域 ✅ 模型选择 - 通用文字 → 通用OCR模型 - 发票/证件 → 行业专用模型(准确率更高) - 表格 → 表格OCR模型(保留结构) - 手写体 → 手写OCR模型 - 英文/中英文混合 → 对应语言的模型 ✅ 后处理纠错 - 利用业务规则校验(如发票位数、身份证格式) - 利用上下文推断(如"O"和"0"、"I"和"l"的混淆) - 多次识别取交集或投票如果说OCR是让RPA能"阅读",那CV就是让RPA能"看见和理解"画面。
━━━ CV核心能力与应用 ━━━ 1. 图像定位(在屏幕/图片中找到目标元素的位置) 应用: 当传统选择器无法定位时,用CV来找到按钮/图标的位置 示例: 在Flash游戏中找到"开始游戏"按钮的坐标 2. 图像比对(判断两张图片/区域是否相同或相似) 应用: 验证操作结果、检测UI变化、监控屏幕变化 示例: 判断支付是否成功的"二维码"是否变成了"支付成功" 3. 物体检测(识别图片中有什么物体以及它们的位置) 应用: 识别商品类别、缺陷检测、数量统计 示例: 识别图片中的商品种类和数量 4. 验证码识别(专门的CV应用) 应用: 自动识别各类图形验证码 示例: 登录时自动识别滑块/字符验证码场景:目标应用使用了自定义绘制的UI控件(非标准Windows控件),传统元素捕获完全无法识别
━━━ CV图像定位方案 ━━━ 传统方式失败: Click("#submit-button") → 报错: 元素找不到! CV方案: Step 1: 准备目标元素的参照图片 截取"提交按钮"的图片 → save as "submit_btn_template.png" (注意: 截取时保留适当的边距,不要太紧贴边缘) Step 2: 使用CV指令在屏幕中查找该图片 cvResult = CV_FindImage( templateImage: "submit_btn_template.png", 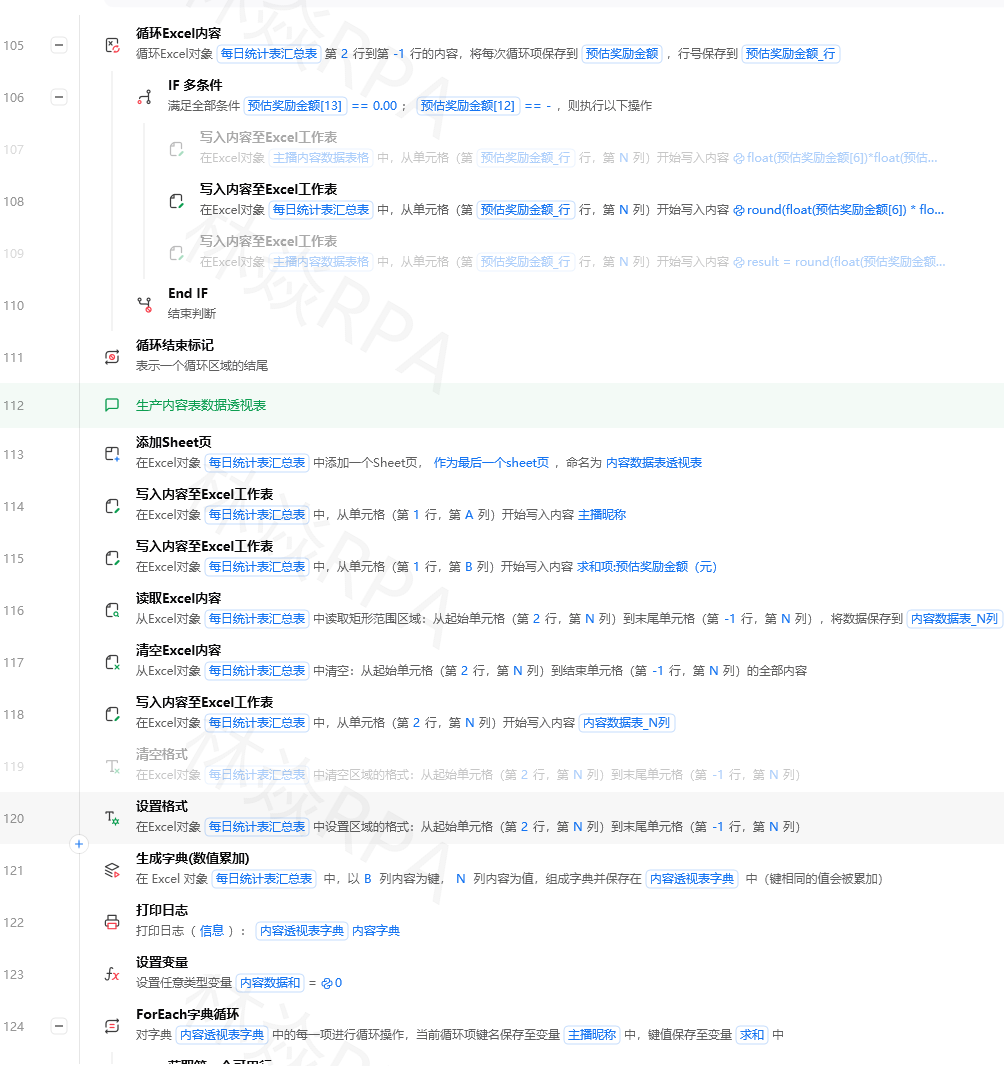 searchArea: "screen", // 在全屏范围内搜索 similarityThreshold: 0.8 // 相似度阈值(0-1) ) Step 3: 根据找到的位置进行操作 If cvResult.found: Click(cvResult.x, cvResult.y) // 在找到的坐标位置点击 LogInfo("CV定位成功! 位置: (" + x + ", " + y + ")") Else: LogError("CV未找到目标图片,相似度最高的匹配: " + cvResult.bestMatchSimilarity) // 可以降低阈值重试,或截图留存供分析━━━ 验证码处理策略 ━━━ 验证码类型及应对: 1. 简单图片验证码(字符/数字) 方案: OCR识别 或 CV+OCR组合 准确率: 80-95%(取决于复杂度) 2. 滑块验证码 方案: CV识别滑块位置 + 模拟拖拽 步骤: a. 截取验证码图片 b. CV识别缺口位置(或滑块需要移动的距离) c. 模拟人类拖拽轨迹(非匀速,带加速度变化) 准确率: 70-90% 3. 点选验证码(按顺序点击指定文字/图片) 方案: OCR/CV识别目标 → 计算坐标 → 依次点击 准确率: 75-95% 4. 旋转验证码(旋转图片到正确角度) 方案: CV图像比对(逐角度尝试匹配) 准确率: 80-95% 5. 行为验证(无图形,检测操作行为) 方案: 模拟真实的人类操作行为模式 (鼠标轨迹、键盘间隔、页面停留等) ⚠️ 重要提醒: - 验证码处理的目的是"提高自动化率"而非100%绕过 - 对于处理不了的验证码,应转入人工处理 - 过度的验证码破解可能违反目标网站的使用条款 - 建议使用官方提供的API接口或申请白名单传统的RPA只能处理高度结构化、规则明确的任务。一旦遇到需要"理解"的场景就力不从心了。
LLM的出现彻底改变了这一局面:
━━━ LLM赋予RPA的新能力 ━━━ 能力1: 自然 Language 理解 Before: 用正则匹配关键词来判断邮件意图(脆弱、不准确) After: LLM阅读邮件全文,理解意图后分类(鲁棒、精准) 能力2: 非结构化信息提取 Before: 用复杂的正则从自由文本中提取字段(难写、易坏) After: 告诉LLM你要什么字段,它自动提取(简洁、准确) 能力3: 内容生成 Before: 只能用固定的模板填空(僵硬、千篇一律) After: LLM根据上下文生成个性化的内容(自然、多样) 能力4: 推理决策 Before: if-else硬编码所有规则(覆盖不了边界情况) After: LLM根据具体情况做出合理的推理和决策(灵活、智能) 能力5: 代码/指令生成 Before: 每种新场景都需要手动编写流程 After: 用自然Language告诉LLM需求,它帮你生成处理逻辑━━━ LLM集成方式 ━━━ 方式1: 影刀内置AI指令(推荐,最简单) 影刀最新版本已内置大模型调用能力 直接拖拽"调用AI模型"指令即可使用 方式2: 通过HTTP API调用 调用OpenAI / 通义千问 / 文心一言 / 智谱等API 用影刀的HTTP请求指令发送请求 方式3: 通过Python SDK调用 在Python扩展中调用各模型的SDK 适合复杂的对话和多轮交互场景案例一:智能邮件分类路由
━━━ LLM邮件分类 ━━━ 输入: 邮件的完整正文内容 Prompt设计: """ 你是一位客服邮件分类助手。请根据以下邮件内容, 判断它属于哪种类型。 分类选项: - product_inquiry(产品咨询) - complaint(投诉/抱怨) - refund_request(退款申请) - technical_support(技术支持) - partnership(商务合作) - other(其他) 请以JSON格式返回结果: {"category": "分类", "confidence": 置信度(0-1), "reason": "理由"} 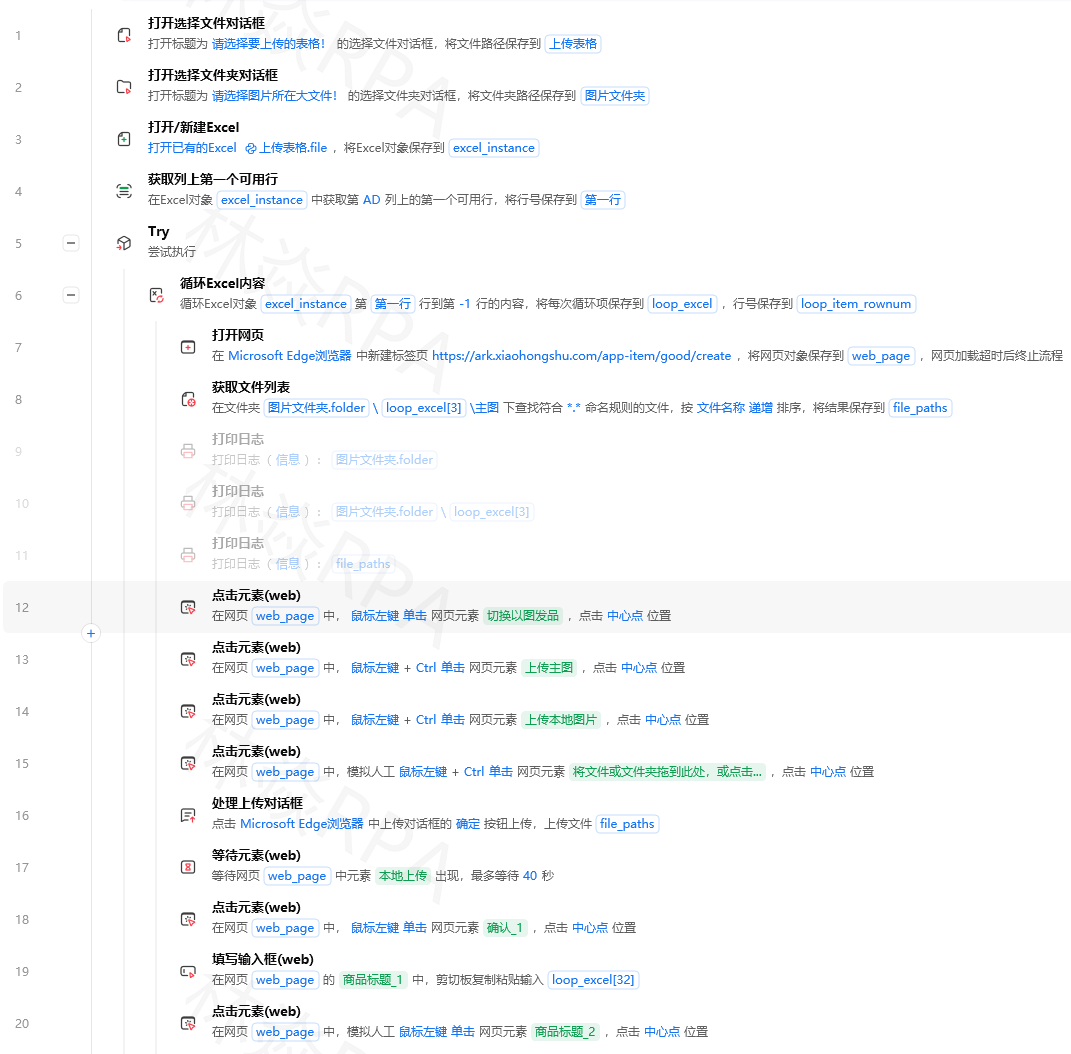 邮件内容: {emailBody} """ 调用: result = CallLLM(prompt, model="gpt-4o-mini") 输出示例: { "category": "complaint", "confidence": 0.92, "reason": "用户明确表达了对产品质量的不满,使用了'太差了' '退货'等词汇,属于投诉类型" } 后续处理: 根据 category 字段路由到对应的处理流程案例二:智能信息提取
━━━ LLM非结构化数据提取 ━━━ 场景: 从客户的需求描述邮件中提取结构化信息 Prompt: """ 请从以下文本中提取以下信息,以JSON格式返回: 1. customer_name(客户姓名) 2. company_name(公司名称) 3. contact_phone(联系电话) 4. product_interest(感兴趣的产品) 5. quantity(预计采购数量) 6. budget(预算范围) 7. urgency(紧急程度: high/medium/low) 如果某项信息未提及,使用null表示。 文本内容: {emailText} """ LLM能很好地处理: "我是华为技术有限公司的李经理,13800138000, 想了解一下你们的企业版产品,大概需要50个账号, 预算在5万左右,这周希望能安排演示" 输出: { "customer_name": "李经理", "company_name": "华为技术有限公司", "contact_phone": "13800138000", "product_interest": "企业版产品", "quantity": 50, "budget": "50000元左右", "urgency": "high" }案例三:自动生成运营文案
TEMU店群如何管理运营?
━━━ LLM文案生成 ━━━ 场景: 根据商品信息自动生成多平台营销文案 输入: 商品的基本信息(名称、特点、价格、目标人群) Prompt: """ 你是一名电商运营专家。请根据以下商品信息, 分别生成适用于小红书、抖音、微信朋友圈的三版文案。 要求: - 小红书: 带emoji表情,种草风格,带话题标签 - 抖音: 口语化,有吸引力,适合短视频脚本 - 朋友圈: 简洁专业,突出卖点 商品信息: 名称: {productName} 特点: {features} 价格: {price} 优惠: {promotion} 目标人群: {targetAudience} """ 输出: 三版不同风格的营销文案 → 直接发布到各平台或交由人工审核后发布单个AI能力已经很有用了,但当它们组合在一起时,威力更是倍增:
━━━ 组合案例: 智能合同审核系统 ━━━ 需求: 自动接收合同扫描件,提取关键条款,审核风险点, 流程设计: Step 1: 文件接收(RPA) └─ 从邮箱下载合同附件(PDF/图片) Step 2: OCR识别(AI-OCR) └─ 将扫描件转为可搜索的文字 └─ 识别结果: 全文文本 + 表格数据 Step 3: 信息提取(AI-LLM) └─ LLM从OCR文本中提取: · 合同甲乙方 · 合同金额 · 签订/生效/到期日期 · 付款条款 · 违约责任 · 特殊约定 Step 4: 风险审核(AI-LLM) └─ LLM根据预设的风险规则审核合同: · 付款条件是否过于苛刻? · 违约责任是否不对等? · 是否有法律风险条款? · 金额/日期是否有异常? Step 5: 报告生成(RPA + LLM) └─ 生成合同审核报告: · 基本信息摘要 · 风险点标注(高/中/低) · 修改建议 · 整体评级(通过/有条件通过/不通过) Step 6: 通知流转(RPA) └─ 发送报告给法务/相关负责人 └─高风险合同同时短信通知━━━ AI成本优化策略 ━━━ AI能力虽强,但不是免费的。需要在效果和成本间取得平衡: 1. 分层使用(不必每步都用AI) 第一层: 传统RPA规则(免费、最快)→ 先用规则处理明确的场景 第二层: 正则/模板匹配(低成本)→ 半结构化数据 第三层: OCR/CV(中等成本)→ 图片/视觉场景 第四层: LLM(相对较高成本)→ 真正需要理解的场景 2. 缓存与复用 相同的内容不要重复调用AI 例如: 同一张发票只需要OCR一次 3. 批量处理 将多个小请求合并为一个批量请求 批量API通常有价格优惠 4. 选择合适规格的模型 简单分类任务 → 用小模型(快速便宜) 复杂推理任务 → 用大模型(准确但贵) 5. 预处理减少Token消耗 先用规则过滤掉不需要AI处理的数据 精简Prompt,去掉冗余内容这篇文章全面介绍了影刀RPA的三大AI能力及其应用:
| AI能力 | 核心价值 | 最适用场景 | 成熟度 |
|---|---|---|---|
| OCR | 让RPA能"阅读" | 证件/票据/扫描件识别 | ⭐⭐⭐⭐⭐ 非常成熟 |
| CV | 让RPA能"看见" | 元素定位/验证码/UI检测 | ⭐⭐⭐⭐ 成熟 |
| LLM | 让RPA能"思考" | 理解/提取/生成/推理 | ⭐⭐⭐ 快速发展中 |
未来已来:RPA与AI的融合是不可逆转的趋势。传统的"基于规则的自动化"正在向"基于智能的自动化"演进。掌握AI能力的RPA开发者,将在未来的职场竞争中拥有巨大的优势。
给你的行动建议:
从OCR开始尝试——门槛最低,效果立竿见影
在实际工作中找到一个需要"看图识字"的场景练手
逐步探索LLM在流程中的切入点
关注影刀官方的AI能力更新,新功能层出不穷
本文由林焱原创,转载请注明出处。AI+RPA,让自动化进入智能时代!