生产环境模型监控实战:从服务健康到数据漂移检测
2026/6/13 23:14:16
品牌舆情、竞品监控、行业话题追踪——这些以前需要人工每天盯着刷微博,用影刀RPA可以全自动完成:定时采集、关键词过滤、情感分类、异常告警。
在开始之前要理解微博的反爬逻辑:
| 特点 | 影响 |
|---|---|
| 需要登录才能看完整内容 | 必须维护登录态 |
| 高频请求会触发人机验证 | 采集间隔不能太短 |
| 搜索结果是时间倒序的 | 增量采集要记录最后一条的时间 |
| 部分内容有折叠展示 | 需要额外操作展开 |
微博的登录带滑块验证,建议流程启动前手动登录一次,然后把Cookie保存下来:
店群矩阵自动化突破运营极限!
importjsonimportosdefsave_weibo_cookies(browser):"""保存微博Cookie到本地"""cookies=browser.get_cookies()# 获取浏览器所有Cookiecookie_path=r'C:\配置\weibo_cookies.json'withopen(cookie_path,'w')asf:json.dump(cookies,f)defload_weibo_cookies(browser):"""加载已保存的Cookie"""cookie_path=r'C:\配置\weibo_cookies.json'ifnotos.path.exists(cookie_path):returnFalse# 没有Cookie,需要手动登录withopen(cookie_path)asf:cookies=json.load(f)# 先打开微博域名browser.open('https://weibo.com')# 注入Cookieforcookieincookies:browser.add_cookie(cookie)browser.refresh()# 刷新页面使Cookie生效returnTrueCookie有效期:微博的Cookie通常7~30天有效。过期会自动跳转到登录页,在流程里检测登录状态,过期时发告警通知手动重新登录。
微博搜索的URL格式:
关键词搜索:https://s.weibo.com/weibo?q={关键词}&typeall=1&suball=1×cope=custom:{开始时间}:{结束时间}&page={页码} 话题搜索:https://s.weibo.com/weibo?q=%23{话题名}%23 时间格式:2026-06-10-0:2026-06-11-0(起始时间:结束时间,精确到小时)
微博搜索结果页的核心元素:
# 每条微博的容器 //div[@action-type="feed_list_item"] # 博主昵称 .//a[@class="name"] # 微博正文 .//p[@node-type="feed_list_content"] # 发布时间 .//p[@node-type="feed_list_content_full"]/../following-sibling::*//*[@class="from"]//a[1]  # 转发数 .//li[@action-type="feed_list_forward"]//span[@class="woo-number-count"] # 评论数 .//li[@action-type="feed_list_comment"]//span[@class="woo-number-count"] # 点赞数 .//li[@action-type="feed_list_like"]//span[@class="woo-number-count"]注意:微博前端代码更新频繁,XPath可能会变。建议用contains而不是精确匹配class名。
每次只采集比上次更新的数据,避免重复:
importjsonfromdatetimeimportdatetimedefload_last_cursor(keyword):"""读取上次采集的最后时间"""cursor_file=fr'C:\数据\微博_游标_{keyword}.json'ifos.path.exists(cursor_file):withopen(cursor_file)asf:returnjson.load(f).get('last_time')returnNone# 首次采集,没有游标defsave_cursor(keyword,last_time):"""保存本次采集的最后时间"""cursor_file=fr'C:\数据\微博_游标_{keyword}.json'withopen(cursor_file,'w')asf:json.dump({'last_time':last_time},f)# 采集逻辑defcollect_incremental(keyword):last_cursor=load_last_cursor(keyword)new_data=[]forpageinrange(1,50):# 最多翻50页[video(video-fHsA499T-1781339046397)(type-csdn)(url-https://live.csdn.net/v/embed/524992)(image-https://v-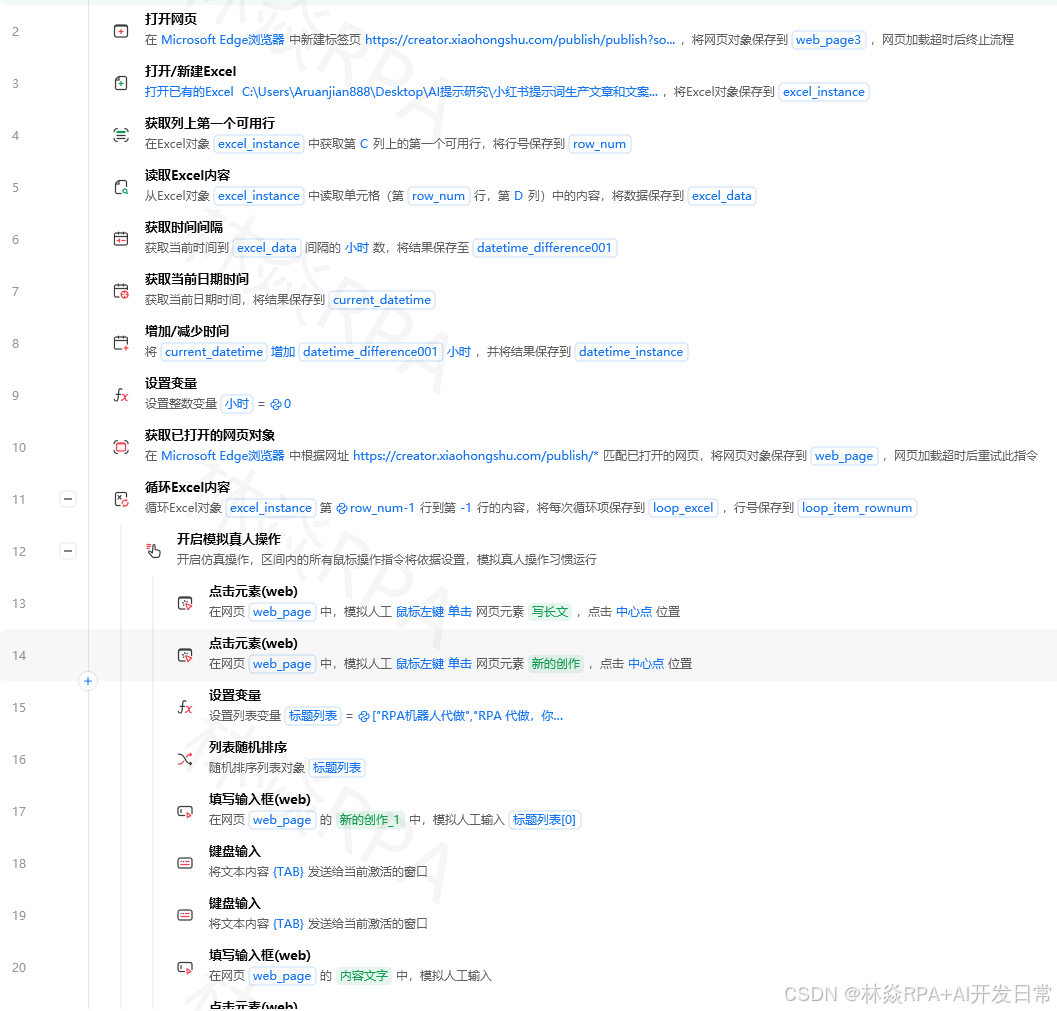blog.csdnimg.cn/asset/b59aed2f01d4fe8583467562aaf4dcfd/cover/Cover0.jpg)(title-temu店群自动化报活动案例)]weibos=collect_page(keyword,page)new_in_page=[]forweiboinweibos:# 如果时间早于上次游标,说明后面都是旧数据iflast_cursorandweibo['time']<=last_cursor:returnnew_data# 终止翻页new_in_page.append(weibo)ifnotnew_in_page:break# 页面没有新数据new_data.extend(new_in_page)random_wait(2,5)# 保存最新的时间作为下次游标ifnew_data:save_cursor(keyword,max(w['time']forwinnew_data))returnnew_data不需要接AI接口,用关键词规则就能做基础情感分类:
defclassify_sentiment(text):"""基于关键词的情感分类"""negative_words=['差评','垃圾','投诉','骗','假货','售后差','踩雷','后悔','不推荐','不好','避雷','翻车','维权']positive_words=['好评','推荐','喜欢','满意','不错','五星','购买了','安利','真香','值得','惊喜']neg_score=sum(1forwinnegative_wordsifwintext)pos_score=sum(1forwinpositive_wordsifwintext)ifneg_score>pos_score:return'负面'elifpos_score>neg_score:return'正面'else:return'中性'进阶:如果需要更准确的情感分析,可以调用百度/腾讯/阿里的情感分析API,影刀Python代码块里直接发HTTP请求就能用。
# 告警判断defcheck_alert(keyword,data):negative_count=sum(1fordindataifd['sentiment']=='负面')total_count=len(data)iftotal_count==0:returnneg_ratio=negative_count/total_count# 负面率超过30%或单小时负面超过50条,发告警ifneg_ratio>0.3ornegative_count>50:send_wecom_message(f'⚠️ 舆情告警\n'f'关键词:{keyword}\n'f'新增{total_count}条,负面{negative_count}条({neg_ratio:.0%})\n'f'请及时关注!')#影刀RPA #RPA自动化 #舆情监控 #微博采集 #品牌监控
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。