SpringBoot集成AJ-Captcha实战:从RedisTemplate空指针到/captcha/get 400无响应排查全解
2026/6/11 11:21:15
影刀的流程指令处理点击、输入、表格读写都很顺手,但一到字符串处理就吃力了。比如从"¥128.00"里把128提取出来、从"已售10万+件"里提取10万、从一堆描述文字里找到手机号。
这些操作用Python的正则表达式(re模块)一行搞定,但有一个前提:Python图标要先点亮。
影刀流程画布左侧的指令面板里,有一个"Python代码"指令。拖到画布上,弹出一个代码编辑器。
注意:左下角的Python图标必须是亮的。如果灰色,点一下它。
代码编辑器里可以写任意Python代码,流程中前面步骤产生的变量可以通过影刀内置的方式获取。
拼多多店群自动化上架方案
电商数据清洗里80%的Python需求,都是这个:
# 从各种格式的价格文本里提取数字importre 价格文本="¥128.00"价格数字=float(re.search(r'\d+\.?\d*',价格文本).group())# 结果:128.0价格文本2="¥ 99.9起"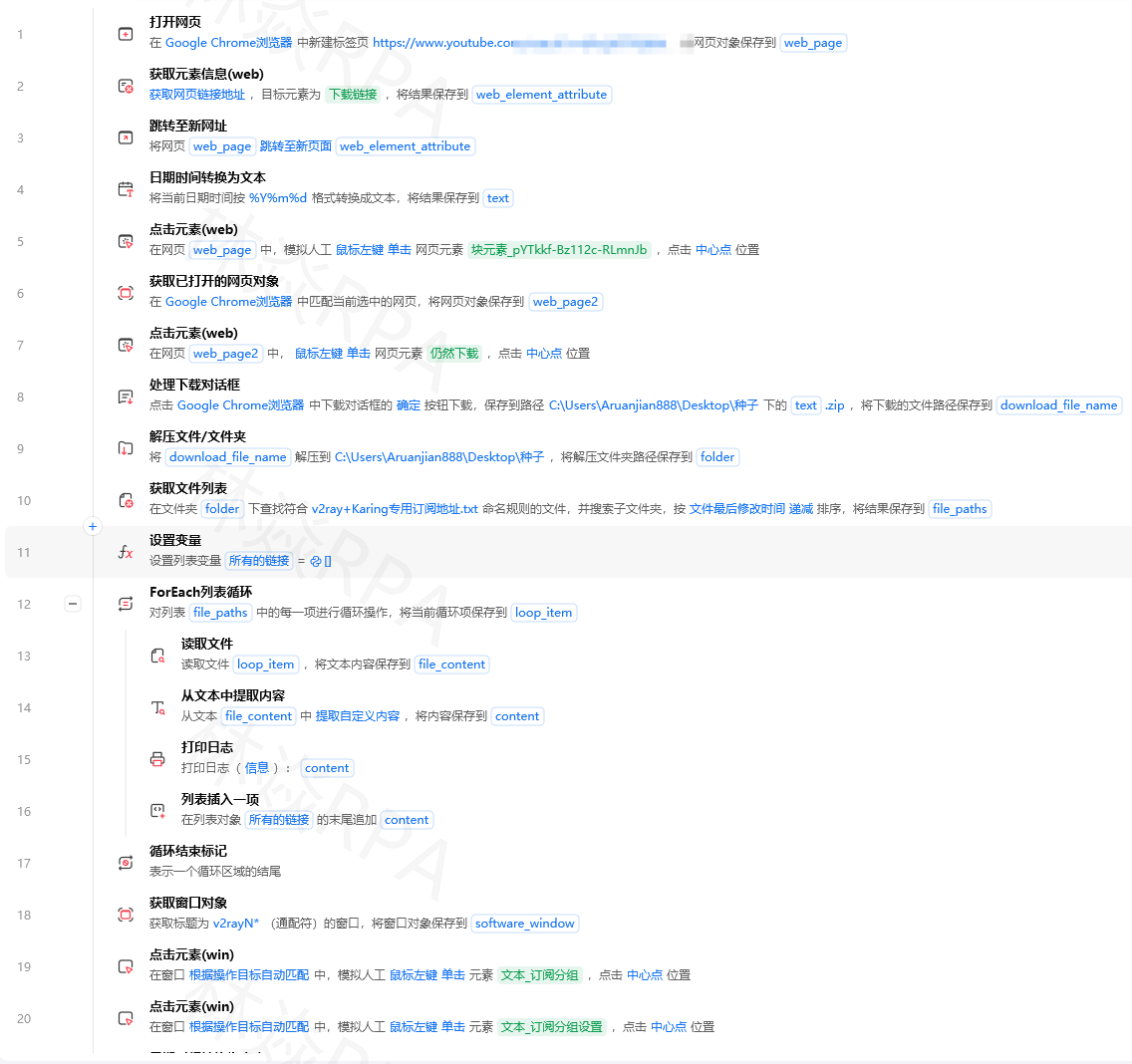价格数字2=float(re.search(r'\d+\.?\d*',价格文本2).group())# 结果:99.9价格文本3="128"价格数字3=float(re.search(r'\d+\.?\d*',价格文本3).group())# 结果:128.0正则解释:\d+\.?\d*
\d+至少一位数字\.?可选的小数点(因为有些价格没有小数位)\d*小数点后的数字(0位或多位)“已拼10万+件” → 需要知道它到底是多少件。
importredefparse_sales(text):"""把各种销量文本转成数字"""text=str(text).replace(' ','')# 找数字部分match=re.search(r'(\d+\.?\d*)',text)ifnotmatch:return0num=float(match.group(1))# 判断单位if'万'intext:num=num*10000elif'亿'intext:num=num*100000000returnint(num)# 测试print(parse_sales("已拼10万+件"))# 100000print(parse_sales("已拼1.2万件"))# 12000print(parse_sales("已拼556件"))# 556print(parse_sales("即将抢光"))# 0importre# 从文本中提取手机号defextract_phone(text):pattern=r'1[3-9]\d{9}'phones=re.findall(pattern,str(text))returnphones[0]ifphoneselse''# 从文本中提取邮箱defextract_email(text):pattern=r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}'emails=re.findall(pattern,str(text))returnemails[0]ifemailselse''# 从文本中提取URLdefextract_url(text):pattern=r'https?://[^\s<>"{}|\\^`\[\]]+'urls=re.findall(pattern,str(text))returnurls# 测试描述="请联系客服微信:13800138000,或发送邮件到service@shop.com"print(extract_phone(描述))# 13800138000print(extract_email(描述))# service@shop.comTEMU店群如何管理运营?
# ===== 去空格和特殊符号 =====text=" 连衣裙 2026新款 "text=text.strip()# 去首尾空格:"连衣裙 2026新款"text=text.replace('\n','')# 去掉换行符text=text.replace('\t',' ')# 把tab换成空格# ===== 截取部分文字 =====标题="【顺丰包邮】夏季连衣裙女法式收腰显瘦2026新款"# 去掉【】内容importre 标题=re.sub(r'【.*?】','',标题)# "夏季连衣裙女法式收腰显瘦2026新款"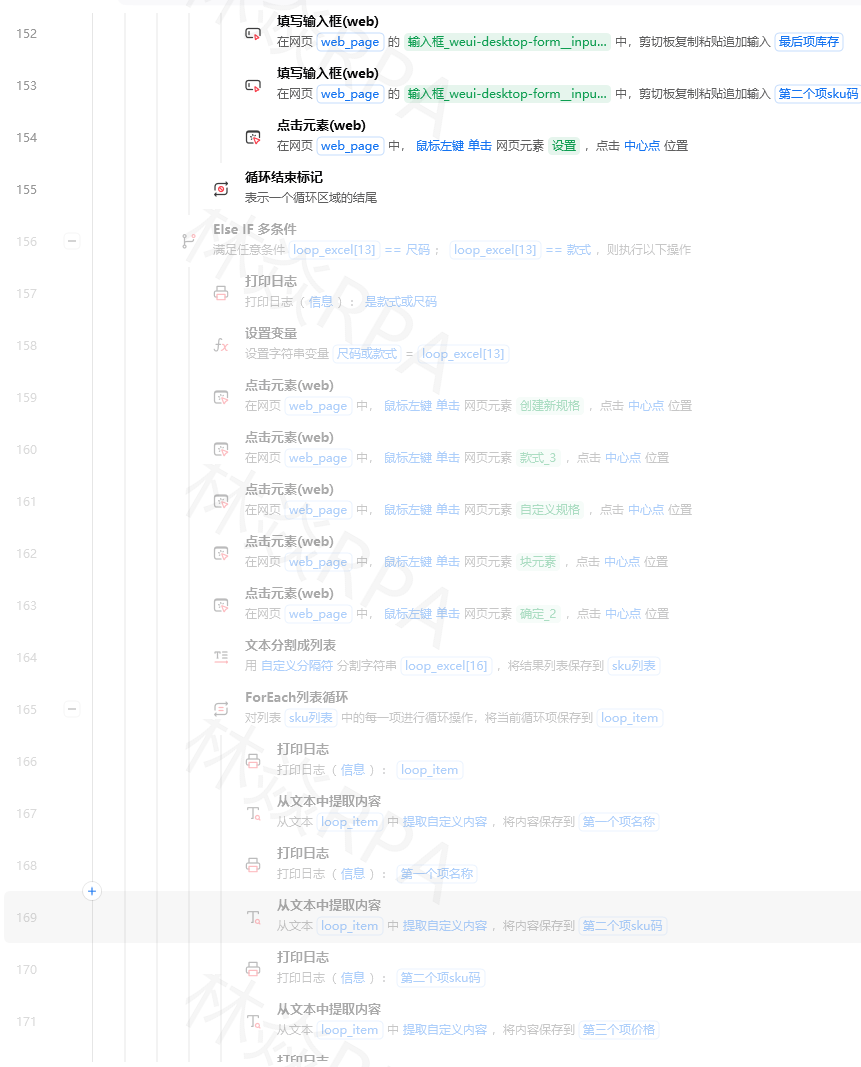# ===== 判断文本包含 =====if'连衣裙'in标题and'2026'in标题:print("是新款连衣裙")# ===== 大小写转换(TEMU英文标题) =====英文标题="Women's Summer Dress 2026 New Arrival"小写=英文标题.lower()# "women's summer dress 2026 new arrival"大写=英文标题.upper()# "WOMEN'S SUMMER DRESS 2026 NEW ARRIVAL"# 影刀流程中采集每条商品时调用Python清洗# === Python代码指令 ===importredefclean_price(price_str):match=re.search(r'\d+\.?\d*',str(price_str))returnfloat(match.group())ifmatchelse0.0defclean_sales(sales_str):text=str(sales_str)match=re.search(r'(\d+\.?\d*)',text)ifnotmatch:return0num=float(match.group(1))if'万'intext:num*=10000if'亿'intext:num*=100000000returnint(num)defclean_title(title_str):# 去掉【】[]包裹的内容title=re.sub(r'[【\[].*?[】\]]','',str(title_str))# 去掉多余空格title=re.sub(r'\s+',' ',title).strip()returntitle# 假设从影刀流程传入:raw_price, raw_sales, raw_title清洗后价格=clean_price(raw_price)清洗后销量=clean_sales(raw_sales)清洗后标题=clean_title(raw_title)# 返回清洗后的数据给影刀后续步骤| 需求 | 正则 | 说明 |
|---|---|---|
| 提取数字 | \d+\.?\d* | 至少一位整数 + 可选小数点 |
| 提取手机号 | 1[3-9]\d{9} | 1开头,第二位3-9,共11位 |
| 提取邮箱 | [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,} | 标准邮箱格式 |
| 提取URL | https?://[^\s<>"]+ | http或https开头的链接 |
| 提取中文 | [\u4e00-\u9fff]+ | 所有中文字符 |
| 去掉HTML标签 | <[^>]+> | 匹配HTML标签替换为空 |
| 去掉空白字符 | \s+ | 空格、tab、换行等 |
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。